

중복 데이터
중복 속성 만들기
MATCH (apollo:Movie
{
title: 'Apollo 13',
tmdbId: 568,
released: '1995-06-30',
imdbRating: 7.6,
genres: ['Drama', 'Adventure', 'IMAX']
})
MATCH (sleep:Movie
{
title: 'Sleepless in Seattle',
tmdbId: 858,
released: '1993-06-25',
imdbRating: 6.8,
genres: ['Comedy', 'Drama', 'Romance']
})
MATCH (hoffa:Movie
{
title: 'Hoffa',
tmdbId: 10410,
released: '1992-12-25',
imdbRating: 6.6,
genres: ['Crime', 'Drama']
})
MATCH (casino:Movie
{
title: 'Casino',
tmdbId: 524,
released: '1995-11-22',
imdbRating: 8.2,
genres: ['Drama','Crime']
})
SET apollo.languages = ['English']
SET sleep.languages = ['English']
SET hoffa.languages = ['English', 'Italian', 'Latin']
SET casino.languages = ['English']속성 삭제 후 노드-관계로 대체하기
- 다양한 속성 정보를 노드에 저장하는 것은 몇 가지 문제점이 있음
- 동일한 데이터 중복
- filter를 위해서 모든 노드를 탐색해야 함
MATCH (m:Movie)
UNWIND m.genres AS genre
MERGE (g:Genre {name: genre})
MERGE (m)-[:IN_GENRE]->(g)
SET m.genres = null
MATCH (m:Movie)
UNWIND m.languages AS language
//=> language 테이블 만들기
WITH language, collect(m) AS movies
//=> Movie 노드를 리스트로 전환하기
MERGE (l:Language {name:language})
//=> Language 테이블 로우를 노드로 만들기
//?? DISTINCT 안 해도 되는 이유?
WITH l, movies
UNWIND movies AS m
//?? Movie를 collect했다 UNWIND했다 하는 이유가 뭐지..?
WITH l,m
MERGE (m)-[:IN_LANGUAGE]->(l);
//=> IN_LANGUAGE 관계 형성
MATCH (m:Movie)
SET m.languages = null
//=>languages 속성 삭제
UNWIND m.languages 의 결과

collect(m) as movie
MATCH (m:Movie)
RETURN collect(m) AS movies
//결과
[
{ "identity": 22,
"labels": ["Movie"],
"properties":
{ "tmdbId": 568,
"genres": ["Drama", "Adventure","IMAX"],
"imdbRating": 7.6,
"title": "Apollo 13",
"released": "1995-06-30"},
"elementId": "22"
}
,
{ "identity": 26,
"labels": ["Movie"],
"properties":
{"tmdbId": 858,
"genres": ["Comedy", "Drama", "Romance"],
"imdbRating": 6.8,
"title": "Sleepless in Seattle",
"released": "1993-06-25"
},
"elementId": "26"
}
,
{ "identity": 27,
"labels": ["Movie"],
"properties":
{ "tmdbId": 10410,
"genres": ["Crime", "Drama"],
"imdbRating": 6.6,
"title": "Hoffa",
"released": "1992-12-25"
},
"elementId": "27"
}
,
{ "identity": 31,
"labels": ["Movie"],
"properties":
{ "tmdbId": 524,
"genres": ["Drama", "Crime"],
"imdbRating": 8.2,
"title": "Casino",
"released": "1995-11-22"
},
"elementId": "31"
}
]
UNWIND movie as m
MATCH (m:Movie)
UNWIND m.languages AS language
WITH language, collect(m) AS movies
UNWIND movies AS m
RETURN m
관계 OR 쿼리
MATCH (p:Person)-[:ACTED_IN_1995|DIRECTED_1995]-()
RETURN p.name as `Actor or Director`apoc.merge.relationship
apoc.merge.relationship
( startNode,
relType,
identProps:{key:value, …},
onCreateProps:{key:value, …},
endNode,
onMatchProps:{key:value, …})
- 관계를 다이나믹 타입으로 머지함.
- ON CREATE or ON MATCH로 속성을 설정함
MATCH (n:Actor)-[r:ACTED_IN]->(m:Movie) CALL apoc.merge.relationship(n, 'ACTED_IN_' + left(m.released,4), {}, m ) YIELD rel RETURN COUNT(*) AS `Number of relationships merged`
MATCH (n:Actor)-[:ACTED_IN]->(m:Movie)
CALL apoc.merge.relationship(n, 'ACTED_IN_' + left(m.released,4), {}, {}, m , {})
YIELD rel
RETURN count(*) AS `Number of relationships merged`;중간 노드를 활용한 모델
중간 노드의 필요성
Hyperedges인 경우 (n-ary relationships)

중간 노드를 생성한 모델
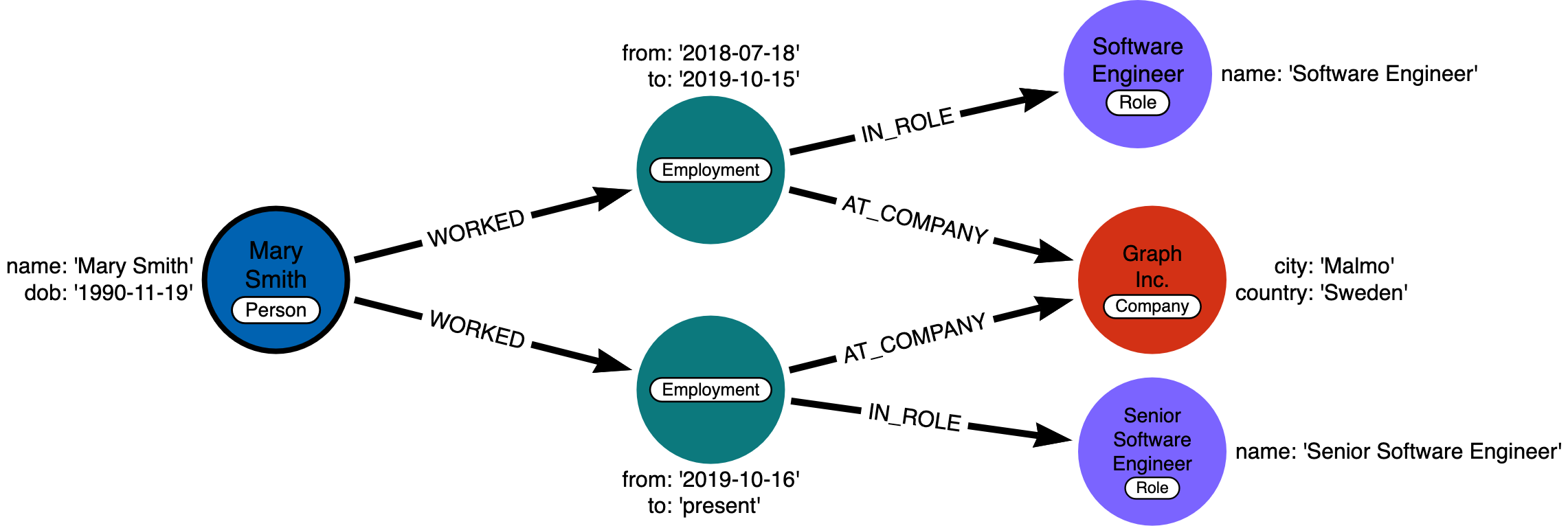
데이터 공유를 위한 중간 노드
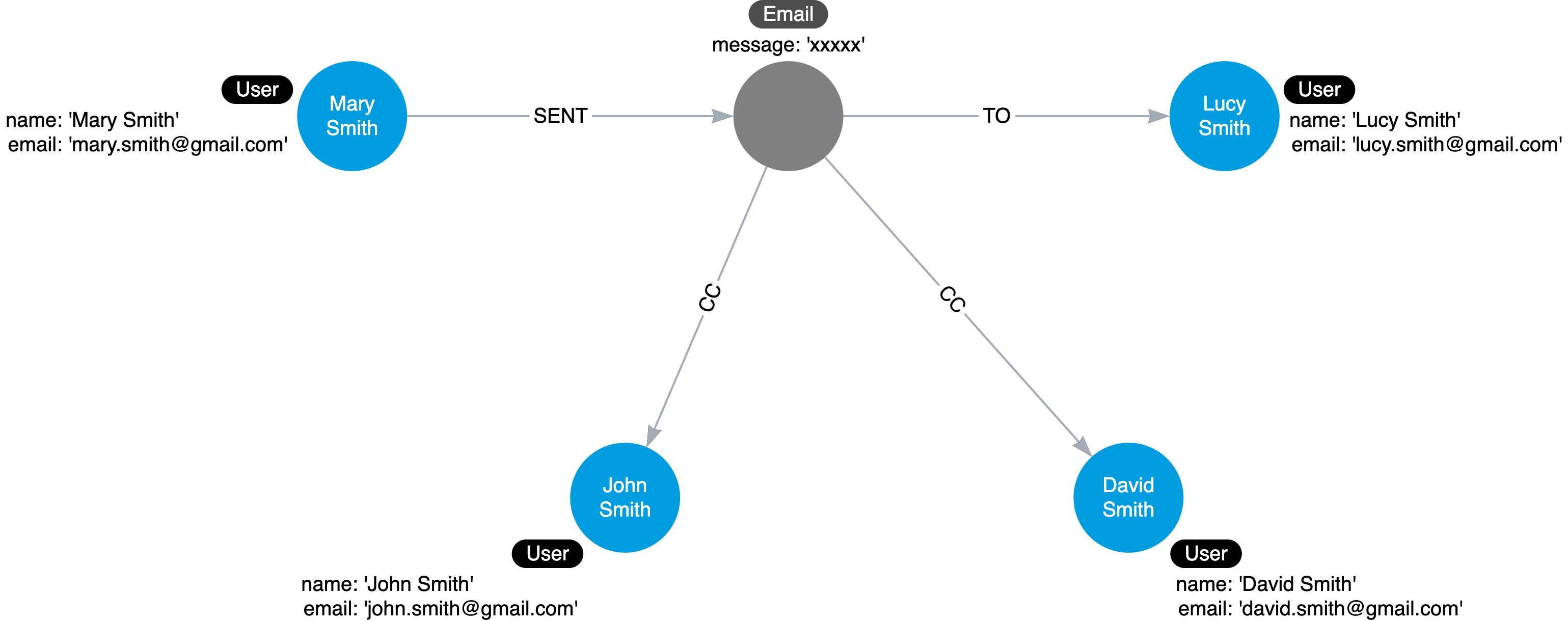
데이터 중복이 있는 경우
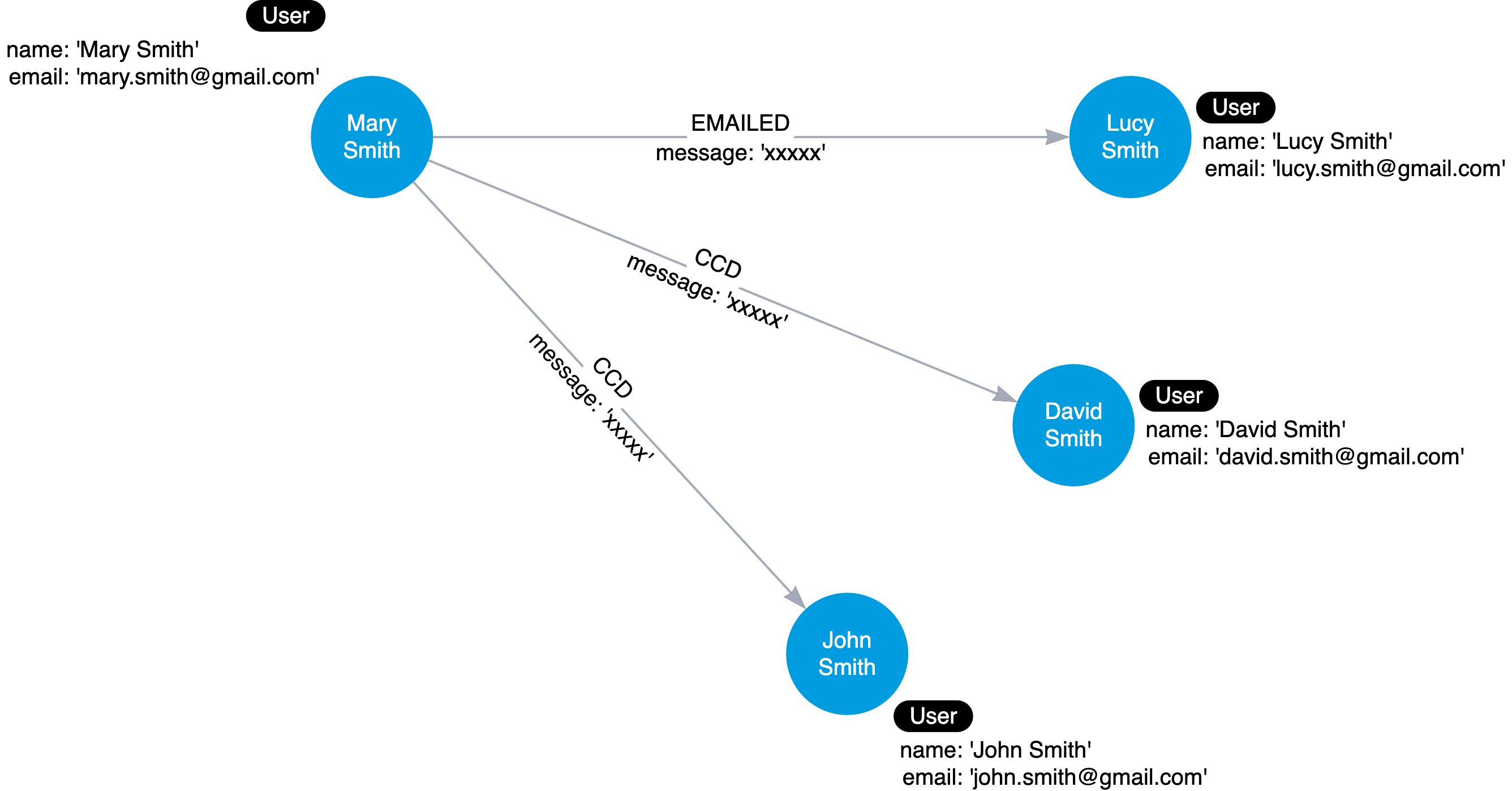
데이터 중복 제거를 위한 중간 노드를 생성한 모델
참고자료: Neo4j 그래프아카데미, Graph Data Modeling Fundamentals
https://graphacademy.neo4j.com/courses/modeling-fundamentals/
'데이터베이스 Database > 그래프DB_Neo4j' 카테고리의 다른 글
| [Neo4j 기초] CSV 파일 임포트해오기 (1) | 2023.02.21 |
|---|---|
| [Neo4j 기초] 그래프 DB 모델링 - 노드/관계 생성 (0) | 2023.02.09 |
| [Neo4j] 기본적인 표기법과 기초 함수 (노드, 관계, MERGE, CREATE, DELETE, SET) (0) | 2023.02.06 |
중복 데이터
중복 속성 만들기
MATCH (apollo:Movie
{
title: 'Apollo 13',
tmdbId: 568,
released: '1995-06-30',
imdbRating: 7.6,
genres: ['Drama', 'Adventure', 'IMAX']
})
MATCH (sleep:Movie
{
title: 'Sleepless in Seattle',
tmdbId: 858,
released: '1993-06-25',
imdbRating: 6.8,
genres: ['Comedy', 'Drama', 'Romance']
})
MATCH (hoffa:Movie
{
title: 'Hoffa',
tmdbId: 10410,
released: '1992-12-25',
imdbRating: 6.6,
genres: ['Crime', 'Drama']
})
MATCH (casino:Movie
{
title: 'Casino',
tmdbId: 524,
released: '1995-11-22',
imdbRating: 8.2,
genres: ['Drama','Crime']
})
SET apollo.languages = ['English']
SET sleep.languages = ['English']
SET hoffa.languages = ['English', 'Italian', 'Latin']
SET casino.languages = ['English']속성 삭제 후 노드-관계로 대체하기
- 다양한 속성 정보를 노드에 저장하는 것은 몇 가지 문제점이 있음
- 동일한 데이터 중복
- filter를 위해서 모든 노드를 탐색해야 함
MATCH (m:Movie)
UNWIND m.genres AS genre
MERGE (g:Genre {name: genre})
MERGE (m)-[:IN_GENRE]->(g)
SET m.genres = null
MATCH (m:Movie)
UNWIND m.languages AS language
//=> language 테이블 만들기
WITH language, collect(m) AS movies
//=> Movie 노드를 리스트로 전환하기
MERGE (l:Language {name:language})
//=> Language 테이블 로우를 노드로 만들기
//?? DISTINCT 안 해도 되는 이유?
WITH l, movies
UNWIND movies AS m
//?? Movie를 collect했다 UNWIND했다 하는 이유가 뭐지..?
WITH l,m
MERGE (m)-[:IN_LANGUAGE]->(l);
//=> IN_LANGUAGE 관계 형성
MATCH (m:Movie)
SET m.languages = null
//=>languages 속성 삭제
UNWIND m.languages 의 결과
collect(m) as movie
MATCH (m:Movie)
RETURN collect(m) AS movies
//결과
[
{ "identity": 22,
"labels": ["Movie"],
"properties":
{ "tmdbId": 568,
"genres": ["Drama", "Adventure","IMAX"],
"imdbRating": 7.6,
"title": "Apollo 13",
"released": "1995-06-30"},
"elementId": "22"
}
,
{ "identity": 26,
"labels": ["Movie"],
"properties":
{"tmdbId": 858,
"genres": ["Comedy", "Drama", "Romance"],
"imdbRating": 6.8,
"title": "Sleepless in Seattle",
"released": "1993-06-25"
},
"elementId": "26"
}
,
{ "identity": 27,
"labels": ["Movie"],
"properties":
{ "tmdbId": 10410,
"genres": ["Crime", "Drama"],
"imdbRating": 6.6,
"title": "Hoffa",
"released": "1992-12-25"
},
"elementId": "27"
}
,
{ "identity": 31,
"labels": ["Movie"],
"properties":
{ "tmdbId": 524,
"genres": ["Drama", "Crime"],
"imdbRating": 8.2,
"title": "Casino",
"released": "1995-11-22"
},
"elementId": "31"
}
]
UNWIND movie as m
MATCH (m:Movie)
UNWIND m.languages AS language
WITH language, collect(m) AS movies
UNWIND movies AS m
RETURN m
관계 OR 쿼리
MATCH (p:Person)-[:ACTED_IN_1995|DIRECTED_1995]-()
RETURN p.name as `Actor or Director`apoc.merge.relationship
apoc.merge.relationship
( startNode,
relType,
identProps:{key:value, …},
onCreateProps:{key:value, …},
endNode,
onMatchProps:{key:value, …})
- 관계를 다이나믹 타입으로 머지함.
- ON CREATE or ON MATCH로 속성을 설정함
MATCH (n:Actor)-[r:ACTED_IN]->(m:Movie) CALL apoc.merge.relationship(n, 'ACTED_IN_' + left(m.released,4), {}, m ) YIELD rel RETURN COUNT(*) ASNumber of relationships merged
MATCH (n:Actor)-[:ACTED_IN]->(m:Movie)
CALL apoc.merge.relationship(n, 'ACTED_IN_' + left(m.released,4), {}, {}, m , {})
YIELD rel
RETURN count(*) AS `Number of relationships merged`;중간 노드를 활용한 모델
중간 노드의 필요성
Hyperedges인 경우 (n-ary relationships)
중간 노드를 생성한 모델
데이터 공유를 위한 중간 노드
데이터 중복이 있는 경우
데이터 중복 제거를 위한 중간 노드를 생성한 모델
참고자료: Neo4j 그래프아카데미, Graph Data Modeling Fundamentals
https://graphacademy.neo4j.com/courses/modeling-fundamentals/
'데이터베이스 Database > 그래프DB_Neo4j' 카테고리의 다른 글
| [Neo4j 기초] CSV 파일 임포트해오기 (1) | 2023.02.21 |
|---|---|
| [Neo4j 기초] 그래프 DB 모델링 - 노드/관계 생성 (0) | 2023.02.09 |
| [Neo4j] 기본적인 표기법과 기초 함수 (노드, 관계, MERGE, CREATE, DELETE, SET) (0) | 2023.02.06 |